
dbt’s Semantic Layer for Dummies
dbt’s Semantic Layer for Dummies
it's me i'm the dummy


I have a life threatening condition. It’s called an allergy to technical jargon. I notice the same patterns with heavy jargon users as I do with purple prose users, and that is that it’s often covering up the fact that the user of these patterns of speech has nothing to say.
You’ve seen what I mean.
It’s the LinkedIn
Posts like this
That have line breaks
Instead of substance
And it’s the data grifters on the internet building an endless parade of SaaS tools with increasingly niche use cases that barely justify a full on subscription, much less a damn incorporated business.
It honestly makes it pretty hard to work in the data sphere sometimes. There’s plenty of good that the modern data stack has brought us. There are also so many different types of businesses in the world and all of them have different data needs, and varying levels of utility for tools that may or may not be niche. Just because I think an ad for a data tool is too niche or dumb doesn’t mean it doesn’t have a use case. I’m simply a tired, grieving woman on the internet with too many opinions and little patience for salesmen refusing to say anything specific about what their product solves for. And even less patience for products that rely on blatant fear or spite mongering to rustle up sales.
So, you could imagine that I had a hard time wrapping my brain around the concept of a semantic layer when it started to get buzz in the data world. Most of the advertising I saw for lots of different types of tools in the semantic layer space was pretty vague.
“Tired of business users getting different answers to the same questions? Sick of losing trust in the data team at your business? Does everyone hate you because you can’t write a damn SUM() WHERE() query?? Try our new semantic layer!! It’s gonna fix all that and more.”
I kinda hate that shit—because anyone, anyone at all, who tells you that their tool and their tool alone is going to solve your data problems is being misleading. It is always going to be a combination of tools and process.
Now. Despite all of my snark and sass above, the explosion of buzz around the semantic layer did catch my eye, because I have had that problem. I have actually had business users trying to get the same answer to a question and failing to do so. As an analyst at my last job, I was often asked to answer questions that seemed simple, but were not. Come join me on a trip down memory lane.
At my last job, one of the focal points of our analyses were counting up devices that were essentially bluetooth receivers at distribution centers. The distribution centers may have been distributing perishable goods like blueberries, or they may have been distributing vaccines, or other things like disease testing kits. Regardless, everything in these distribution centers required close temperature monitoring. The bluetooth receivers at these centers picked up data from bluetooth monitors, and sent the data to our platform for analysis.
You could imagine that it would be pretty important for us to know how many bluetooth receivers we had at different distribution centers. You might also think that this is a simple question to answer. So maybe it’s fine that when a business stakeholder wanted to know how many receivers were active for a certain company, they went to an engineer who knew how to write SQL instead of me, the busy one-woman analytics team who wasn’t always very fast with ad-hoc questions.
You could absolutely be forgiven for that assumption. But then you might feel as frustrated as I did when I did get to performing this ad-hoc count of bluetooth receivers and I got a different answer than the engineer who allegedly did the same task. How hard could it be to count up pieces of hardware? Well, let’s break down some context around why it wasn’t actually an easy question.
Our fulfillment team kept their own records of receivers being shipped to distribution centers. These records did not say anything about whether the receiver was actually turned on and successfully receiving data, merely the fact that the receiver was sent to a distribution center, and where the distribution center was. It was not uncommon for time to elapse between a receiver being sent to a distribution center and the device actually being turned on and working. The engineer who got a different count than me worked closer to fulfillment data.
The data team kept our own records of these receivers. We did not work with the shipping side of these receivers. We had information on which receivers were on and working, and access to the data that they offloaded into our platform. When I performed a count of receivers, I assumed that the asker wanted a count of working receivers that had offloaded data successfully , and not simply a count of receivers overall.
We had to compare SQL queries with a fairly fine-toothed comb to figure out why our answers differed from one another.
This is one of the hazards of the dream of self-serve data, right? Ideally, we want it to be okay that Mr. Engineer went to the data on his own and helped out a business stakeholder with a quick question. But neither of us got enough context around what additional contextual information was needed for this count, we wrote different SQL queries, and we got different answers.
Ideally, a semantic layer is supposed to solve this problem. Using dbt’s Semantic Layer as an example, let’s take a high-level look at the mechanics of how the right combination of tools and process could have solved this problem. 1
What’s dbt’s Semantic Layer (powered by MetricFlow baby) supposed to do anyways?
Individual humans writing SQL will not write identical queries. They are thus susceptible to writing slightly different queries to answer questions and getting slightly different answers.
dbt’s Semantic Layer says, hey, what if we abstracted that away and asked a piece of software to dynamically generate queries for us?
Now there’s a thought. What if we had that piece of software? It wouldn’t be magic, no software is. We’d have to tell it how to operate in our database’s context. This would mean providing it information such as:
Our database credentials
Which tables we want it to be able to dynamically generate queries (that will calculate metrics) from
What’s inside those tables (i.e., what’s a dimension vs. a measure in those tables)
What columns in those tables can serve as join keys
What we want it to do when we need to pull certain metrics that get used regularly in our business
One thing at a time here.
In the scenario above, let’s pretend like we have the semantic layer, and like we’re calling it our dynamic query generator, or query generator for short. To make our query generator work for us, we have to figure out how to answer the following questions.
Which tables do we want the query generator to be able to dynamically make queries from?
In dbt’s Semantic Layer, we’d need to configure semantic models to to tell the query generator that it can work with that table. In this solution, those semantic models are configured using YAML files.
In my work scenario, I would have told the query generator that the receiver lifecycle table was the right semantic model to pull from.
What’s inside those tables?
Our query generator won’t know how to build queries (that will calculate metrics) if we don’t tell it what’s inside the tables. We have to configure dimensions and measures to tell the query generator which columns it should use in GROUP BYs versus which columns are aggregate-able.
I would have told the query generator that the categorical columns were dimensions, and the numerical columns were measures, within my receiver lifecycle table.
What columns in those tables can serve as join keys?
Usually, when you’re building queries yourself, it’s not just from one table. Our query generator can join tables for us, but it’s not going to know how to do so unless we tell it the columns in the table that can serve as join keys. In dbt’s semantic layer, those columns are referred to as entities and generally are designated as primary or foreign—same as primary and foreign keys.
I would have told the query generator that the primary entity of the receiver semantic model was the receiver’s serial number.
What do we want it to do when we need to calculate certain metrics that get used regularly in our business?
We have to tell our query generator how to combine or aggregate measures and then slice or group them by dimensions in order to make metrics. This is done by deciding what kind of metric you are calculating, and then configuring it accordingly using the metrics documentation.
For us, this would have been a simple-type metric with a SUM and a filter—where the filter was only summing bluetooth receivers that had offloaded data successfully at least once.
Once we’ve told our query generator all of those things, we need to hook it up to an integration. At this point, for dbt’s Semantic Layer, this includes familiar players like Tableau, Google Sheets, and Hex. Full list is available here. Once we get the semantic layer hooked up to our integration, we’ll have an interface that might look something like this screenshot.
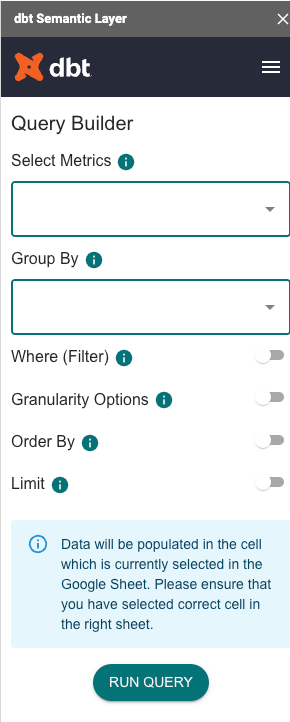
We’ll choose the metric RECEIVER COUNT and group by CUSTOMER NAME. The query generator will build a query for us in the background, and spit the results out in our integrated tool. That way, all we have to do when multiple people are wanting the same answer to a question, is choose the right inputs. Then, myself and Mr. Engineer aren’t going to argue about our counts of receivers, because ideally, we both know how to choose the right inputs and hit a button.
So like…did the semantic layer solve all our problems?! I mean, probably not. But standardizing ad-hoc queries like this is pretty dang cool and might make lots of folks’ days less frustrating. I think it’s pretty sweet.
See you next week. Don’t forget to subscribe, tell your friends, the whole 9 yards.
sure, we could talk this through using another semantic layer tool. But I’m gonna be real with you—I’m not Switzerland. I do prefer dbt’s approach to problem solving and I have no obligation to treat all available solutions equally. There’s lots of other tech writers out there that compare and contrast semantic layer solutions. I’m just trying to bloom where I’m planted
This is a fantastic piece. Truly. I’ve been struggling to understand the point of the “semantic layer” and the real world example you gave of counting up the devices is super helpful. As an aside, and this obv isn’t your problem or a criticism of your piece at all, but I still feel lost as to the utility of doing all that work because it still doesn’t solve the problem of Mr. Engineer wanting to use a totally different source to answer the question. Like, if the data team has their own warehouse and the fulfillment team has their own warehouse and the org can’t get on the same page as to which one makes sense as the right source for a count of devices, why would a semantic layer sitting on top of the data team’s warehouse solve that problem? Is the idea that the business user would stop asking Mr. Engineer questions like that altogether because pivoting out the answer in their BI tool themselves is truly “self service”?
I’m writing something about data standardization as well — but a little bit more unhinged — as always, great post